When looking at under the hood architecture for Cloud leaders, we immediately see 2 common things:
- Few disclosed figures make you feel dizzy (yes, 1 Peta = 1000 Tera…)
- Very few technical infos disclosed
What happen is that Google & Azure recently let some infos going out for their network 🙂
Facebook is more ahead and provide more information.
Microsoft Azure
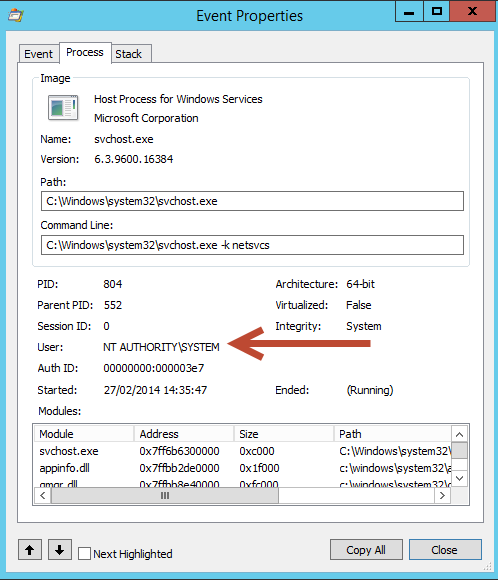
About Azure, here are slides from Russinovich master (click on image to get PowerPoint (29 slides)):

Most important news: they use FPGA (programmable processors) to manage network layer (40GbE/s) (or to mine bitcoins, who knows!).
Last time I had valuable informations was at TechEd in 2012, again from Mark. Video is still online:
- ~10 people to admin around 100 000 servers!
- Demo of one of the Azure admin interface,
- Graphical view of racks with VM,
- Demo on platform self healing,
- Explain on leap day bug (29th of february), with even source code line that broke everything
Looks like they index evertything excep their own architecture content (with a killer robots.txt 😉
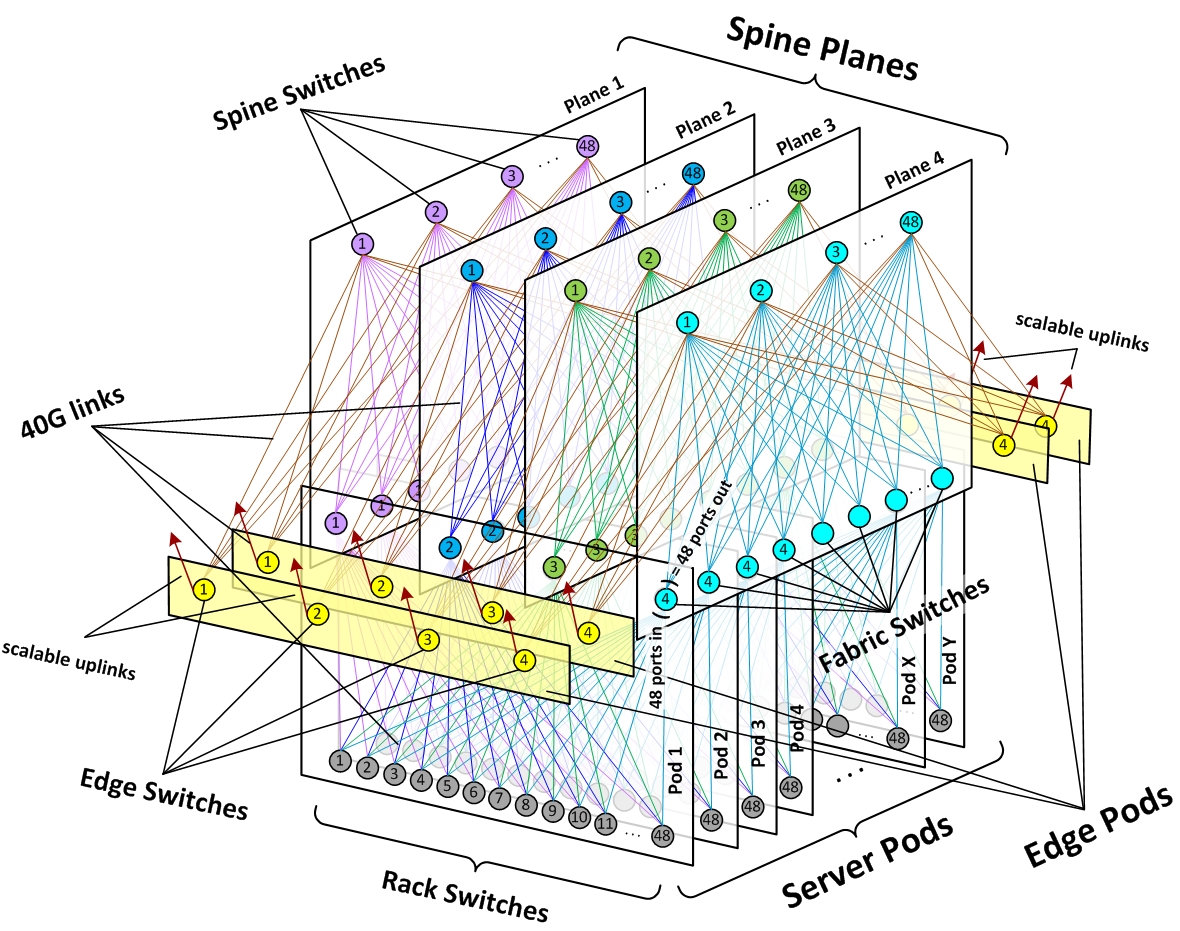
Techcrunch collected interesting infos, again on their network management (SDN):
http://techcrunch.com/2015/06/17/google-pulls-back-curtain-on-its-data-center-networking-setup/
In 2009, They had published a visite in their datacenter, with a server content inside a container:

They are more chatty, may be frm their DNA…:
Figure 2:
A Facebook server (old model I guess):

Empty at the back is true:

Office365
Most information are about Exchange:
- Backup less,
- 3 replicate + 1 Lag at 8 days (goes down to 0 in case of issues)
- JBOD storage (1 database per hard drive).
- Optimizations through Exchange 2016
Office 365 is independent from Azure, while some services are using it and merge is upcoming I guess.
Amazon
- They are using Xen for virtualization,
- They also make their own server,
- Based on Open source
Conclusions
They have hyper needs, but also hyper resources to handle them:
- Complete control of the entire chain: datacenter, network, servers, OS, hypervisor, applications, load balancers, SQL engines
- Developments in low layers : SDN, FPGA…
- Source code (and people to handle it): Windows for Microsoft, Linux for Google, Facebook and Amazon
- They use Open source (OpenFlow, memcache, Hadoop…) but extend them,
- If they think so, they can spend huge money on topics (like Google with its SDN).
All this gives them a strong independence from other enterprises and their potential buyouts. Other topics may cost less from quantity point of view (ie: earning $50 per server, x300 000)
Where we generally happily stop (geo cluster, DRP, LB) it’s minimum to provide for them. Once this done, another road open with load.